| Summary: Understanding high-performance computing system reliability characteristics requires analyzing system records. The amounts of data and the complexity of the underlying problem are often beyond what can be processed and comprehended by humans. This solution offers a taxonomy, a catalog and models that capture the observed and inferred fault, error and failure conditions in current supercomputers and extrapolates this knowledge to future systems. |
Resilience, i.e., obtaining a correct solution in a timely and efficient manner, is a key challenge in extreme-scale high-performance computing (HPC). Heterogeneity, i.e., using multiple, and potentially configurable, types of processors, accelerators and memory/storage in a single platform, adds significant complexity to the HPC hardware/software ecosystem. The notion of correct computation and program state assumed today, which is based on the von Neumann model, will no longer hold for some emerging technologies, such as for analog circuits that model spiking neurons in neuromorphic computing elements. The diverse set of compute and memory components in future systems will require novel resilience solutions. Resilience needs to be an integral part of the heterogeneous HPC hardware/software ecosystem by design, which requires an understanding of the resilience problem in these systems.
Identifying and modeling HPC system reliability characteristics requires analyzing system records, such as reliability, availability and serviceability logs. The amounts of data and complexity of the underlying problem are often beyond what can be processed and comprehended by humans. Identifying linear and non-linear correlations to timely detect abnormal behavior is needed to mitigate impact on user productivity. This work creates a fault taxonomy, catalog and models that capture the observed and inferred conditions in current operational supercomputers and extrapolates this knowledge to future-generation systems.
For example, failure characteristics evolved over five generations of supercomputers at the Oak Ridge Leadership Computing Facility (OLCF) and certain lessons were learned from characterizing these systems. The studied systems are Jaguar XT4, Jaguar XT5, Jaguar XK6, Eos and Titan. We analyzed systems logs from January 2008 to September 2015, a total of 11.26 system years or 1.22 billion node hours. The results of this analysis show that the mean-time between failures (MTBF) is not a good indicator of system reliability, which has been the traditional method (Figure 1). A set of dominant failure types is common across systems. Only very few types contribute most of the failures for each system. The set of major contributors can change significantly over time (Figure 2).
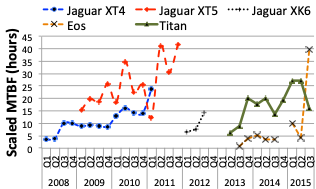 Figure 1: Scaled MTBF for Jaguar, Titan, and Eos at OLCF |
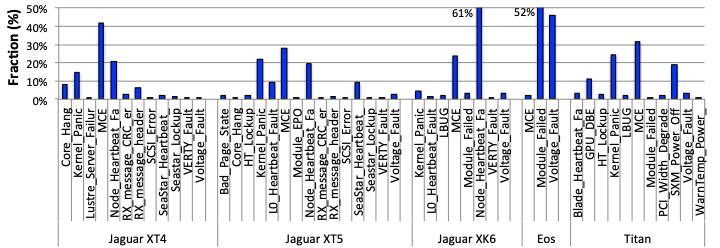 Figure 2: Dominant failure types for Jaguar, Titan, and Eos at OLCF |
In another example, the Cray XK7 Titan was the fastest supercomputer in the world for a long time and remained critically important throughout its nearly seven year life. It was an interesting machine from a reliability viewpoint as most of its power came from 18,688 GPUs whose operation was forced to execute three rework cycles, two on the general-purpose computing on graphics processing units (GPGPU) mechanical assembly and one on the GPGPU circuitboards. The last rework cycle (Figure 3) required a reliability analysis of over 100,000 years of GPGPU lifetimes during Titan’s 6-year-long productive period. Using time between failures analysis and statistical survival analysis techniques, GPGPU reliability was found to be dependent on heat dissipation to an extent that strongly correlates with detailed nuances of the cooling architecture and job scheduling (Figures 4 and 5).
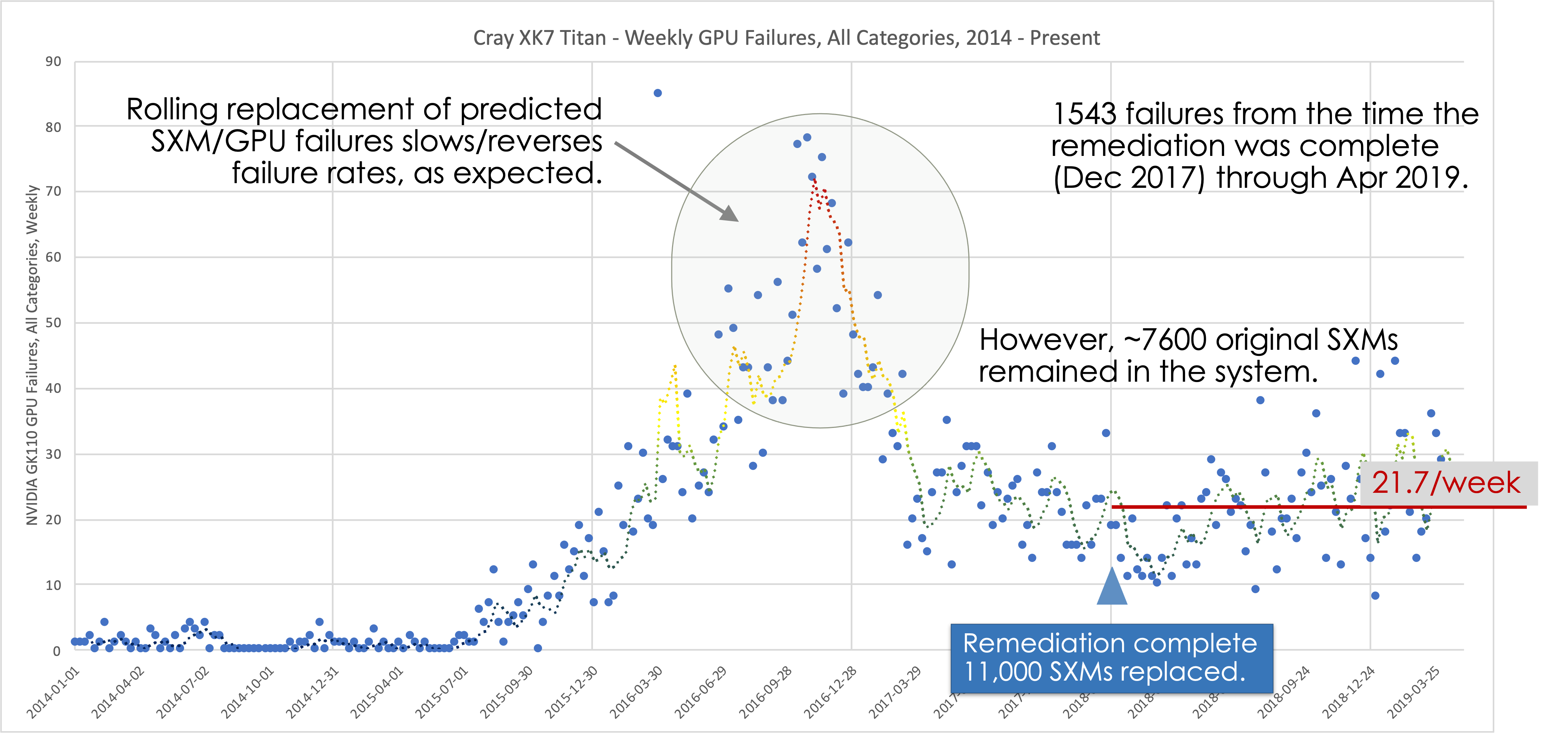 Figure 3: Silver sulfide corrosion of a resistor on Titan’s GPGPU circuit board caused severe reliability issues and the replacement of 11,000 out of 18,688 GPGPUs |
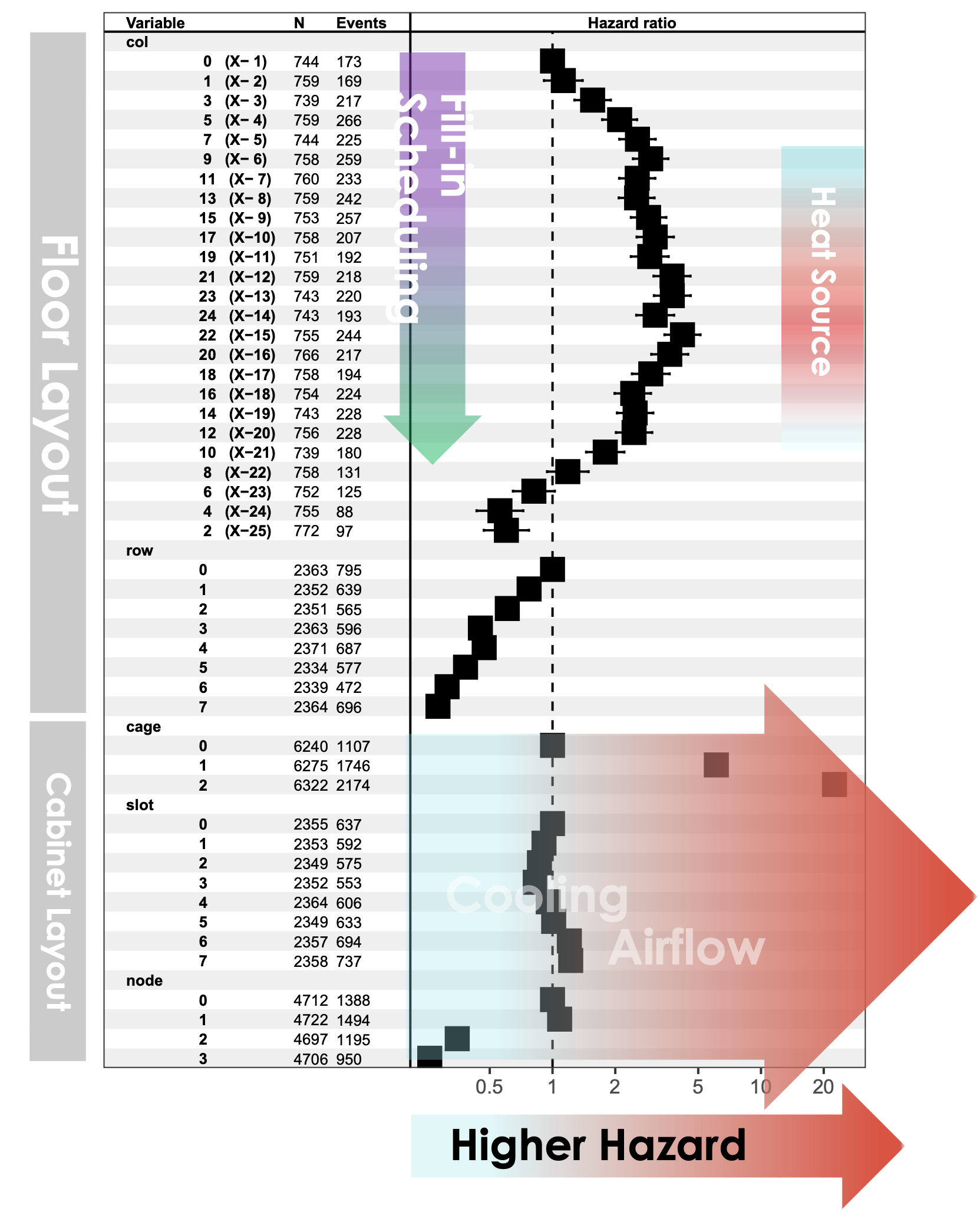 Figure 5: Cox proportional hazards show how room cooling architecture and fill-in scheduling affect GPGPU reliability |
|
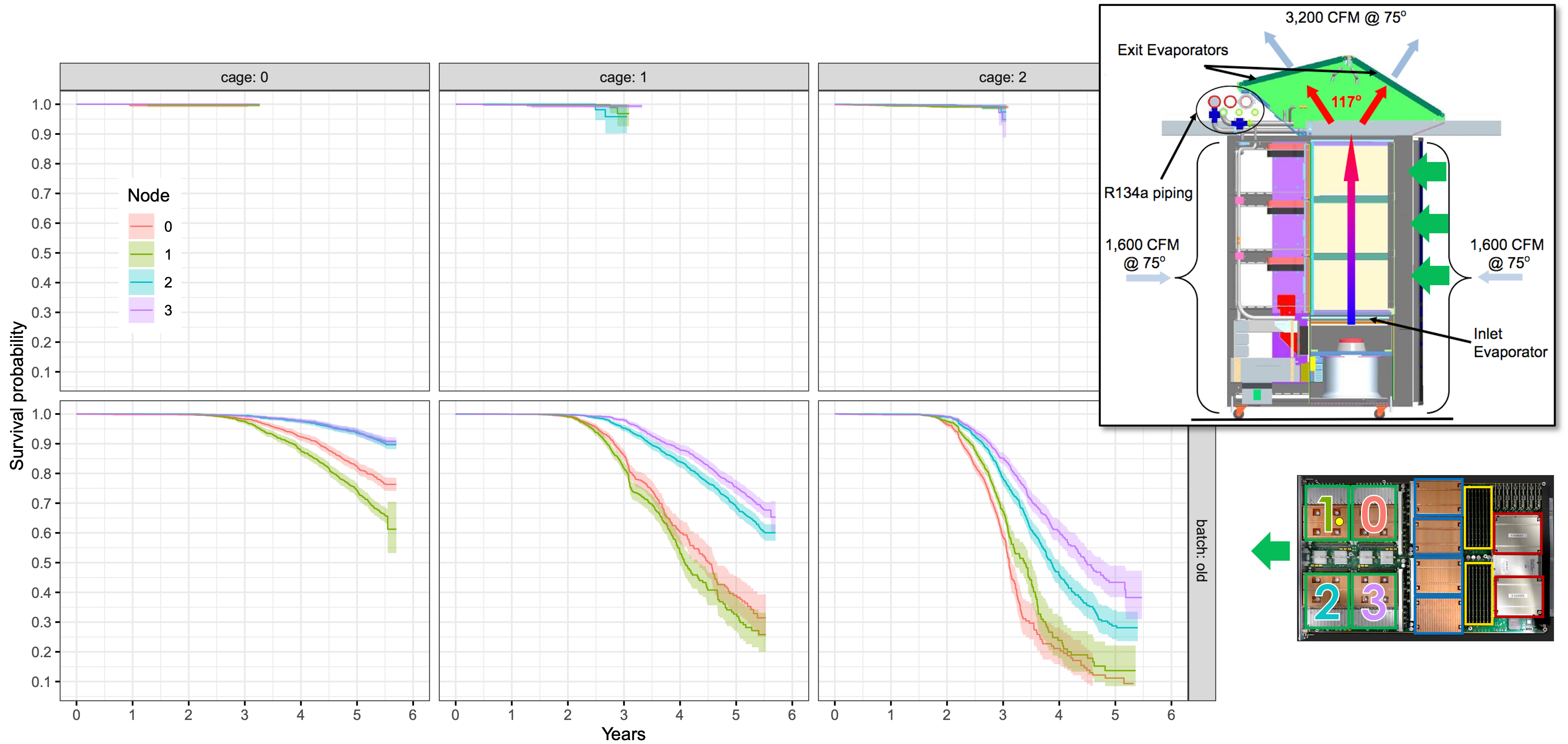 Figure 4: GPGPU survival probability depending on cage and node location explainable by airflow in the cabinet |
Research Projects
- 2015-19: Catalog: Characterizing Faults, Errors, and Failures in Extreme-Scale Systems
- 2008-11: Reliability, Availability, and Serviceability (RAS) for Petascale High-End Computing and Beyond
Funding Sources
- Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy
Participating Institutions
- Oak Ridge National Laboratory
- Lawrence Livermore National Laboratory
- Argonne National Laboratory
- Louisiana Tech University
In the News
2021-01-04: HPCwire. What’s New in HPC Research: GPU Lifetimes, the Square Kilometre Array, Support Tickets & More.
2018-11-19: HPCwire. What’s New in HPC Research: Thrill for Big Data, Scaling Resilience and More.
2018-08-05: inside HPC. Characterizing Faults, Errors and Failures in Extreme-Scale Computing Systems.
Peer-reviewed Journal Publications
- Mohit Kumar, Saurabh Gupta, Tirthak Patel, Michael Wilder, Weisong Shi, Song Fu, Christian Engelmann, and Devesh Tiwari. Study of Interconnect Errors, Network Congestion, and Applications Characteristics for Throttle Prediction on a Large Scale HPC System. Journal of Parallel and Distributed Computing (JPDC), volume 153, pages 29-43, July 1, 2021. Elsevier B.V, Amsterdam, The Netherlands. ISSN 0743-7315. DOI 10.1016/j.jpdc.2021.03.001.



- Marc Snir, Robert W. Wisniewski, Jacob A. Abraham, Sarita V. Adve, Saurabh Bagchi, Pavan Balaji, Jim Belak, Pradip Bose, Franck Cappello, Bill Carlson, Andrew A. Chien, Paul Coteus, Nathan A. Debardeleben, Pedro Diniz, Christian Engelmann, Mattan Erez, Saverio Fazzari, Al Geist, Rinku Gupta, Fred Johnson, Sriram Krishnamoorthy, Sven Leyffer, Dean Liberty, Subhasish Mitra, Todd Munson, Rob Schreiber, Jon Stearley, and Eric Van Hensbergen. Addressing Failures in Exascale Computing. International Journal of High Performance Computing Applications (IJHPCA), volume 28, number 2, pages 127-171, May 1, 2014. SAGE Publications. ISSN 1094-3420. DOI 10.1177/1094342014522573.
Peer-reviewed Conference Publications
- Vladyslav Oles, Anna Schmedding, George Ostrouchov, Woong Shi, Evgenia Smirni, and Christian Engelmann. Understanding GPU Memory Corruption at Extreme Scale: The Summit Case Study. In Proceedings of the 38th ACM International Conference on Supercomputing (ICS) 2024, pages 188-200, Kyoto, Japan, June 4-7, 2024. ACM Press, New York, NY, USA. ISBN 979-8-4007-0610-3. DOI 10.1145/3650200.3656615. Acceptance rate 36.0% (45/125).

- George Ostrouchov, Don Maxwell, Rizwan Ashraf, Christian Engelmann, Mallikarjun Shankar, and James Rogers. GPU Lifetimes on Titan Supercomputer: Survival Analysis and Reliability. In Proceedings of the 33rd IEEE/ACM International Conference on High Performance Computing, Networking, Storage and Analysis (SC) 2020, pages 41:1-14, Atlanta, GA, USA, November 15-20, 2020. ACM Press, New York, NY, USA. ISBN 9781728199986. DOI 10.1109/SC41405.2020.00045. Acceptance rate 25.1% (95/378).
- Mohit Kumar, Saurabh Gupta, Tirthak Patel, Michael Wilder, Weisong Shi, Song Fu, Christian Engelmann, and Devesh Tiwari. Understanding and Analyzing Interconnect Errors and Network Congestion on a Large Scale HPC System. In Proceedings of the 48th IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) 2018, pages 107-114, Luxembourg City, Luxembourg, June 25-28, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-5596-2. ISSN 2158-3927. DOI 10.1109/DSN.2018.00023. Acceptance rate 27.2% (62/228).
- Bin Nie, Ji Xue, Saurabh Gupta, Tirthak Patel, Christian Engelmann, Evgenia Smirni, and Devesh Tiwari. Machine Learning Models for GPU Error Prediction in a Large Scale HPC System. In Proceedings of the 48th IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) 2018, pages 95-106, Luxembourg City, Luxembourg, June 25-28, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-5596-2. ISSN 2158-3927. DOI 10.1109/DSN.2018.00022. Acceptance rate 27.2% (62/228).
- Saurabh Gupta, Tirthak Patel, Christian Engelmann, and Devesh Tiwari. Failures in Large Scale Systems: Long-term Measurement, Analysis, and Implications. In Proceedings of the 30th IEEE/ACM International Conference on High Performance Computing, Networking, Storage and Analysis (SC) 2017, pages 44:1-44:12, Denver, CO, USA, November 12-17, 2017. ACM Press, New York, NY, USA. ISBN 978-1-4503-5114-0. DOI 10.1145/3126908.3126937. Acceptance rate 18.7% (61/327).
- Bin Nie, Ji Xue, Saurabh Gupta, Christian Engelmann, Evgenia Smirni, and Devesh Tiwari. Characterizing Temperature, Power, and Soft-Error Behaviors in Data Center Systems: Insights, Challenges, and Opportunities. In Proceedings of the 25th IEEE International Symposium on the Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS) 2017, pages 22-31, Banff, AB, Canada, September 20-22, 2017. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-2764-8. ISSN 2375-0227. DOI 10.1109/MASCOTS.2017.12. Acceptance rate 30.95% (26/84).
- Kun Tang, Devesh Tiwari, Saurabh Gupta, Ping Huang, QiQi Lu, Christian Engelmann, and Xubin He. Power-Capping Aware Checkpointing: On the Interplay Among Power-Capping, Temperature, Reliability, Performance, and Energy. In Proceedings of the 46th IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) 2016, pages 311-322, Toulouse, France, June 28 – July 1, 2016. IEEE Computer Society, Los Alamitos, CA, USA. ISSN 2158-3927. DOI 10.1109/DSN.2016.36. Acceptance rate 22.4% (58/259).
- Leonardo Bautista-Gomez, Ana Gainaru, Swann Perarnau, Devesh Tiwari, Saurabh Gupta, Franck Cappello, Christian Engelmann, and Marc Snir. Reducing Waste in Extreme Scale Systems Through Introspective Analysis. In Proceedings of the 30th IEEE International Parallel and Distributed Processing Symposium (IPDPS) 2016, pages 212-221, Chicago, IL, USA, May 23-27, 2016. IEEE Computer Society, Los Alamitos, CA, USA. ISSN 1530-2075. DOI 10.1109/IPDPS.2016.100. Acceptance rate 23.0% (114/496).
- Narate Taerat, Nichamon Naksinehaboon, Clayton Chandler, James Elliott, Chokchai (Box) Leangsuksun, George Ostrouchov, Stephen L. Scott, and Christian Engelmann. Blue Gene/L Log Analysis and Time to Interrupt Estimation. In Proceedings of the 4th International Conference on Availability, Reliability and Security (ARES) 2009, pages 173-180, Fukuoka, Japan, March 16-19, 2009. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-4244-3572-2. DOI 10.1109/ARES.2009.105. Acceptance rate 25.0% (40/160).
Peer-reviewed Workshop Publications
- Yawei Hui, Byung Hoon (Hoony) Park, and Christian Engelmann. A Comprehensive Informative Metric for Analyzing HPC System Status using the LogSCAN Platform. In Proceedings of the 31st International Conference on High Performance Computing, Networking, Storage and Analysis (SC) Workshops 2018: 8th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2018, pages 29-38, Dallas, TX, USA, November 16, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-7281-0222-1. DOI 10.1109/FTXS.2018.00007. Acceptance rate 45.0% (9/20).
- Rizwan Ashraf and Christian Engelmann. Analyzing the Impact of System Reliability Events on Applications in the Titan Supercomputer. In Proceedings of the 31st International Conference on High Performance Computing, Networking, Storage and Analysis (SC) Workshops 2018: 8th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2018, pages 39-48, Dallas, TX, USA, November 16, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-7281-0222-1. DOI 10.1109/FTXS.2018.00008. Acceptance rate 45.0% (9/20).
- Byung Hoon (Hoony) Park, Yawei Hui, Swen Boehm, Rizwan Ashraf, Christian Engelmann, and Christopher Layton. A Big Data Analytics Framework for HPC Log Data: Three Case Studies Using the Titan Supercomputer Log. In Proceedings of the 19th IEEE International Conference on Cluster Computing (Cluster) 2018: 5th Workshop on Monitoring and Analysis for High Performance Systems Plus Applications (HPCMASPA) 2018, pages 571-579, Belfast, UK, September 10, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-8319-4. ISSN 2168-9253. DOI 10.1109/CLUSTER.2018.00073.
- Byung Hoon (Hoony) Park, Saurabh Hukerikar, Christian Engelmann, and Ryan Adamson. Big Data Meets HPC Log Analytics: Scalable Approach to Understanding Systems at Extreme Scale. In Proceedings of the 18th IEEE International Conference on Cluster Computing (Cluster) 2017: 4th Workshop on Monitoring and Analysis for High Performance Systems Plus Applications (HPCMASPA) 2017, pages 758-765, Honolulu, HI, USA, September 5, 2017. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-2327-5. ISSN 2168-9253. DOI 10.1109/CLUSTER.2017.113.
- George Ostrouchov, Thomas Naughton, Christian Engelmann, Geoffroy R. Vallée, and Stephen L. Scott. Nonparametric Multivariate Anomaly Analysis in Support of HPC Resilience. In Proceedings of the 5th IEEE International Conference on e-Science (e-Science) 2009: Workshop on Computational Science, pages 80-85, Oxford, UK, December 9-11, 2009. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-4244-5946-9. DOI 10.1109/ESCIW.2009.5407992.
Peer-reviewed Conference Posters
- Yawei Hui, Rizwan Ashraf, Byung Hoon (Hoony) Park, and Christian Engelmann. Real-Time Assessment of Supercomputer Status by a Comprehensive Informative Metric through Streaming Processing. Poster at the 6th IEEE International Conference on Big Data (BigData) 2018, Seattle, WA, USA, December 10-13, 2018.
- Yawei Hui, Byung Hoon (Hoony) Park, and Christian Engelmann. A Comprehensive Informative Metric for Summarizing HPC System Status. Poster at the 8th IEEE Symposium on Large Data Analysis and Visualization in conjunction with the 8th IEEE Vis 2018, Berlin, Germany, October 21, 2018.
White Papers
- Mingyan Li, Robert A. Bridges, Pablo Moriano, Christian Engelmann, Feiyi Wang, and Ryan Adamson. Toward Effective Security/Reliability Situational Awareness via Concurrent Security-or-Fault Analytics . White paper accepted at the U.S. Department of Energy's ASCR Workshop on Cybersecurity and Privacy for Scientific Computing Ecosystems, November 3-5, 2021.
- Petar Radojkovic, Manolis Marazakis, Paul Carpenter, Reiley Jeyapaul, Dimitris Gizopoulos, Martin Schulz, Adria Armejach, Eduard Ayguade, François Bodin, Ramon Canal, Franck Cappello, Fabien Chaix, Guillaume Colin de Verdiere, Said Derradji, Stefano Di Carlo, Christian Engelmann, Ignacio Laguna, Miquel Moreto, Onur Mutlu, Lazaros Papadopoulos, Olly Perks, Manolis Ploumidis, Bezhad Salami, Yanos Sazeides, Dimitrios Soudris, Yiannis Sourdis, Per Stenstrom, Samuel Thibault, Will Toms, and Osman Unsal. Towards Resilient EU HPC Systems: A Blueprint. White paper by the European HPC resilience initiative, April 9, 2020.
- Devesh Tiwari, Saurabh Gupta, and Christian Engelmann. Lightweight, Actionable Analytical Tools Based on Statistical Learning for Efficient System Operations. White paper accepted at the U.S. Department of Energy's Workshop on Modeling & Simulation of Systems & Applications (ModSim) 2016, August 10-12, 2016.
- Marc Snir, and Robert W. Wisniewski, Jacob A. Abraham, Sarita V. Adve, Saurabh Bagchi, Pavan Balaji, Bill Carlson, Andrew A. Chien, Pedro Diniz, Christian Engelmann, Rinku Gupta, Fred Johnson, Jim Belak, Pradip Bose, Franck Cappello, Paul Coteus, Nathan A. Debardeleben, Mattan Erez, Saverio Fazzari, Al Geist, Sriram Krishnamoorthy, Sven Leyffer, Dean Liberty, Subhasish Mitra, Todd Munson, Rob Schreiber, Jon Stearley, and Eric Van Hensbergen. Addressing Failures in Exascale Computing. Workshop report, August 4-11, 2013.
- Al Geist, Bob Lucas, Marc Snir, Shekhar Borkar, Eric Roman, Mootaz Elnozahy, Bert Still, Andrew Chien, Robert Clay, John Wu, Christian Engelmann, Nathan DeBardeleben, Rob Ross, Larry Kaplan, Martin Schulz, Mike Heroux, Sriram Krishnamoorthy, Lucy Nowell, Abhinav Vishnu, and Lee-Ann Talley. U.S. Department of Energy Fault Management Workshop. Workshop report for the U.S. Department of Energy, June 6, 2012.
- Nathan DeBardeleben, James Laros, John T. Daly, Stephen L. Scott, Christian Engelmann, and Bill Harrod. High-End Computing Resilience: Analysis of Issues Facing the HEC Community and Path-Forward for Research and Development. White paper for the U.S. National Science Foundation's High-end Computing Program, December 1, 2009.
Talks and Lectures
- Christian Engelmann. Designing Smart and Resilient Extreme-Scale Systems. Invited talk at the 20th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2022, Seattle, WA, USA, February 23-26, 2022.
- Christian Engelmann. Faults, Errors and Failures in Extreme-Scale Supercomputers. Keynote talk at the 14th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, held in conjunction with the 27th European Conference on Parallel and Distributed Computing (Euro-Par) 2021, Lisbon, Portugal, August 30, 2021.
- Christian Engelmann. The Resilience Problem in Extreme Scale Computing: Experiences and the Path Forward. Invited talk at the SIAM Conference on Computational Science and Engineering (CSE) 2021, Fort Worth, TX, USA, March 1-5, 2021.
- Christian Engelmann. Smart and Resilient Extreme-Scale Systems. Invited talk at the Workshop on Resilience in High Performance Computing (RESILIENTHPC), held in conjunction with the European Network on High-performance Embedded Architecture and Compilation (HiPEAC) Conference 2021, Budapest, Hungary, January 19, 2021.
- Christian Engelmann. The Resilience Problem in Extreme Scale Computing. Invited talk at the 19th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2020, Seattle, WA, USA, February 12-15, 2020.
- Christian Engelmann. Resilience for Extreme Scale Systems: Understanding the Problem. Invited talk at the SIAM Conference on Computational Science and Engineering (CSE) 2019, Spokane, WA, USA, February 25 – March 1, 2018.
- Christian Engelmann. Characterizing Faults, Errors, and Failures in Extreme-Scale Systems. Invited talk at the Platform for Advanced Scientific Computing (PASC) Conference 2018, Basel, Switzerland, July 2-4, 2018.
- Christian Engelmann. Characterizing Faults, Errors, and Failures in Extreme-Scale Systems. Invited talk at the 6th Accelerated Data Analytics and Computing (ADAC) Institute Workshop, Zurich, Switzerland, June 20-21, 2018.
- Christian Engelmann. A Catalog of Faults, Errors, and Failures in Extreme-Scale Systems. Invited talk at the SIAM Annual Meeting (AM) 2017, Pittsburgh, PA, USA, July 10-14, 2017.
- Christian Engelmann. Characterizing Faults, Errors and Failures in Extreme-Scale Computing Systems. Invited talk at the International Supercomputing Conference (ISC) 2017, Frankfurt am Main, Germany, June 16-22, 2017.
- Christian Engelmann. A Catalog of Faults, Errors, and Failures in Extreme-Scale Systems. Invited talk at the 12th Scheduling for Large Scale Systems Workshop (SLSSW) 2017, Knoxville, TN, USA, May 24-26, 2017.
- Christian Engelmann. The Missing High-Performance Computing Fault Model. Invited talk at the 17th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2016, Paris, France, April 12-15, 2016.
- Christian Engelmann. Resilience Challenges and Solutions for Extreme-Scale Supercomputing. Invited talk at the United States Naval Academy, Annapolis, MD, USA, February 18, 2016.
- Christian Engelmann. Toward A Fault Model And Resilience Design Patterns For Extreme Scale Systems. Keynote talk at the 8th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, held in conjunction with the 21st European Conference on Parallel and Distributed Computing (Euro-Par) 2015, Vienna, Austria, August 24-28, 2015.
- Christian Engelmann. High-End Computing Resilience: Analysis of Issues Facing the HEC Community and Path Forward for Research and Development. Invited talk at the Argonne National Laboratory (ANL) Institute of Computing in Science (ICiS) Summer Workshop Week on Addressing Failures in Exascale Computing, Park City, UT, USA, August 4-11, 2012.
- Christian Engelmann. Resilience Challenges at the Exascale. Talk at the 14th Workshop on Distributed Supercomputing (SOS) 2010, Savannah, GA, USA, March 8-11, 2010.
- Christian Engelmann. Modeling Techniques Towards Resilience. Invited talk at the National HPC Workshop on Resilience 2009, Arlington, VA, USA, August 12-14, 2009.
Symbols: Abstract, Publication, Presentation, BibTeX Citation